
We want to generate images locally. Several different applications can do this. To get started, we choose Stable Diffusion WebUI. This tool provides both text-image and image-image generation capabilities.
The WebUI part offers a user interface. Users can select image generation models, set up these models, and generate images from text.
Installing Stable Diffusion and the WebUI
A simple procedure for setting up this tool can be found here. We used the installation procedure for AUTOMATIC1111 on Apple Silicon. We created a simple shell script to launch the tool. Another good resource is the git repository for Stable Diffusion.
# Location where AI tools are installed
cd ~/AI/stable-diffusion-webui
# Log startup of Stable Diffusion
echo "*** Launching Stable Difussion at `date` ***" >> ~/AI/ai.log
# Run Stable Difussion using login/password; enable API
./webui.sh --api --listen --gradio-auth <uid>:<password> >> ~/AI/ai.logWe also used the Mac Automator to launch it when logging in.
The final step is to allow access to the WebUI via a proxy host, our Nginx Proxy Manager.
Choosing and Downloading Models
Once Stable Diffusion is installed, you’ll want to download models to generate images. A good source for models is Hugging Face. Here’s a guide to choosing models. We have these models installed here –
Learning To Use Stable Diffusion

The quality and look of the images you can generate using Stable Diffusion are endless. You can control how your images look and their content through the choices that you make in –
- Your image prompt
- The model you use
- The settings you use to set up your model
You can find a beginner’s guide to Stable Diffusion here.
Generating Images Using Text LLMs
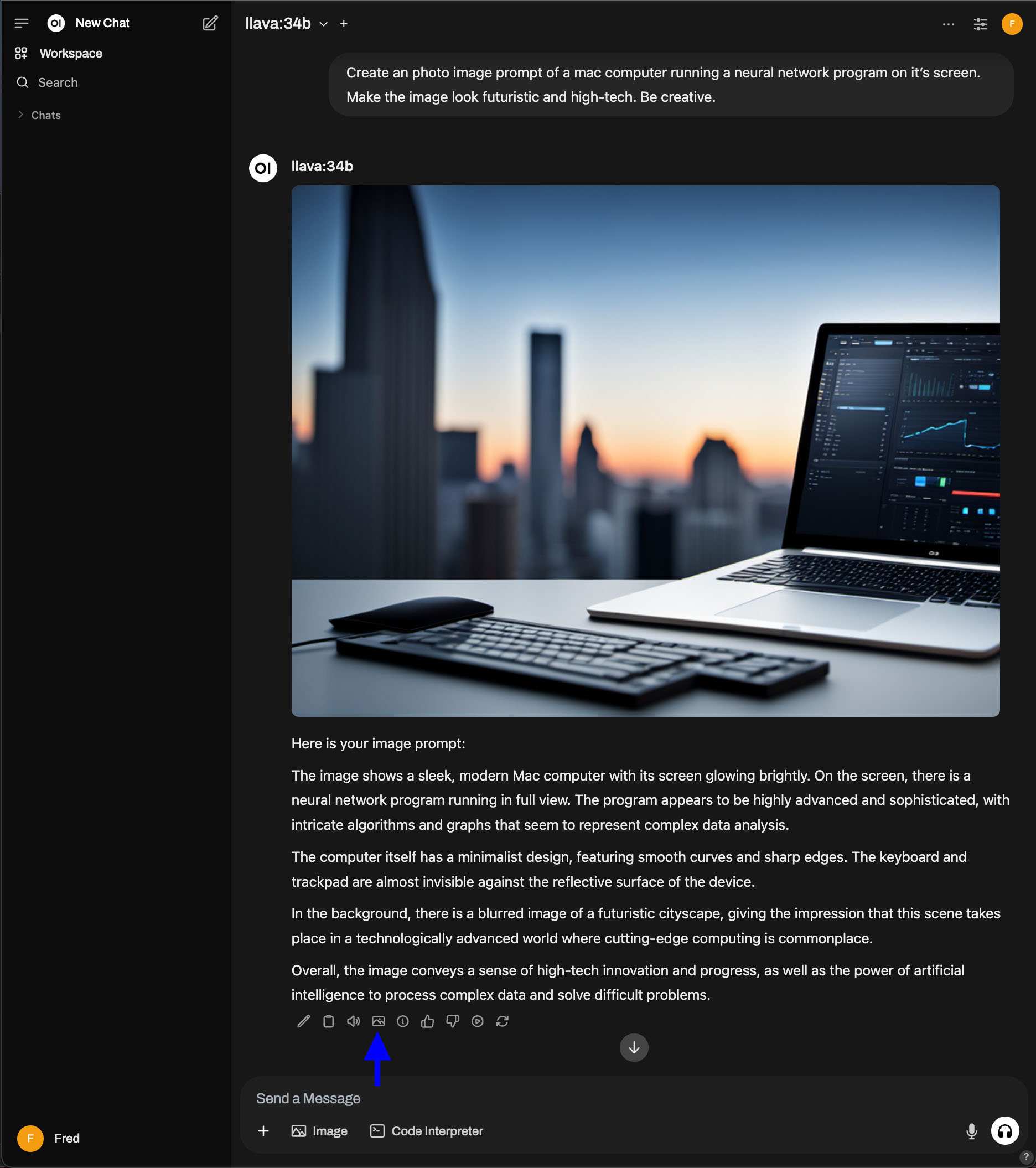
The associated image generation engine can be used from Open WebUI to generate images from text created by LLMs. The steps to do this are as follows.
Configuring Open WebUI to Generate Images
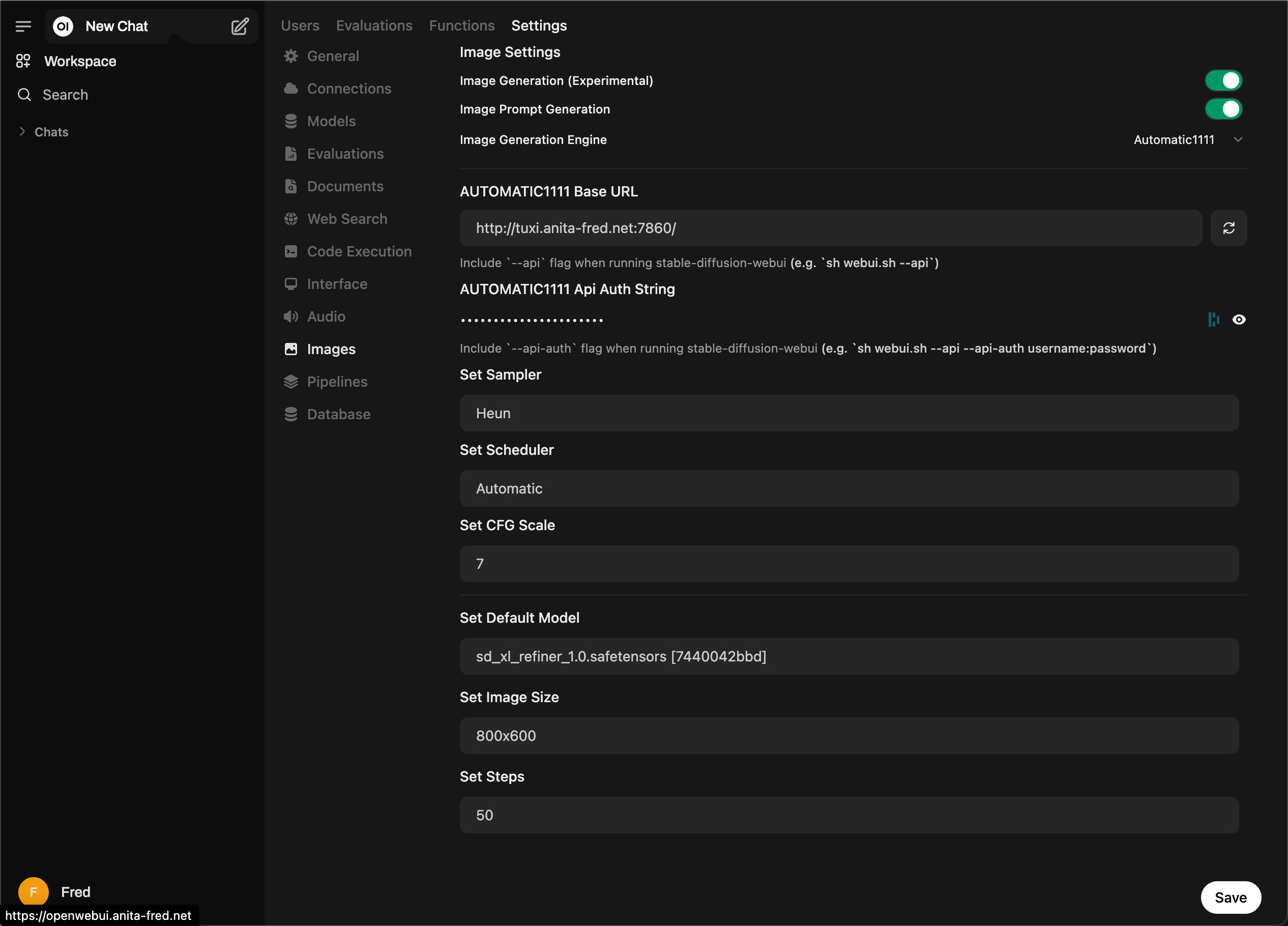
First, you will need to set up Open WebUI image generation. Our current configuration is as follows:
- Use a text LLM like llava:34b to generate an Image Prompt describing the desired image.
- Select the generate image button (shown above the blue arrow in the image) to run your configured image generation model.
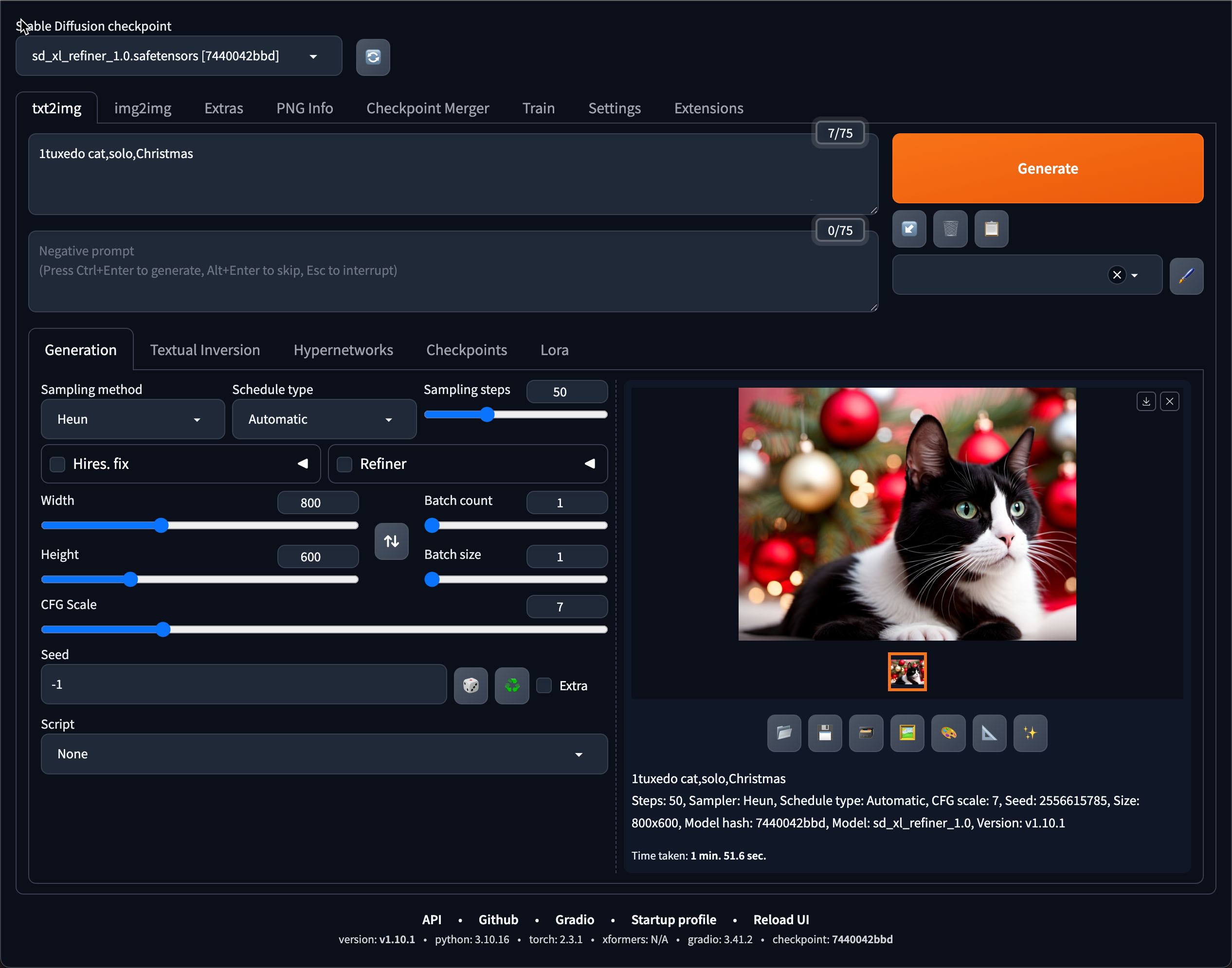
- sd_xl_refiner1.0 – the base model used to generate images
- Heun Sampler – A high-quality image convergence algorithm
- CFG Scale is set to 7 – sets how closely the image prompt is followed during image generation.
- Image Size is 800×600 – the size of the images in pixels.
- Steps is set to 50, which is the number of steps used to refine the image based on your prompt.
You can experiment with these settings using the Stable Diffusion WebUI. This will help you find a combination that produces good results on your setup.